



More on Technology

Gajus Kuizinas
1 year ago
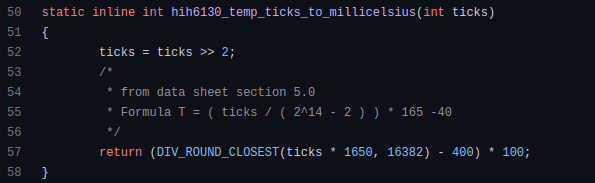
How a few lines of code were able to eliminate a few million queries from the database
I was entering tens of millions of records per hour when I first published Slonik PostgreSQL client for Node.js. The data being entered was usually flat, making it straightforward to use INSERT INTO ... SELECT * FROM unnset() pattern. I advocated the unnest approach for inserting rows in groups (that was part I).

However, today I’ve found a better way: jsonb_to_recordset.
jsonb_to_recordsetexpands the top-level JSON array of objects to a set of rows having the composite type defined by an AS clause.
jsonb_to_recordset allows us to query and insert records from arbitrary JSON, like unnest. Since we're giving JSON to PostgreSQL instead of unnest, the final format is more expressive and powerful.
SELECT *
FROM json_to_recordset('[{"name":"John","tags":["foo","bar"]},{"name":"Jane","tags":["baz"]}]')
AS t1(name text, tags text[]);
name | tags
------+-----------
John | {foo,bar}
Jane | {baz}
(2 rows)Let’s demonstrate how you would use it to insert data.
Inserting data using json_to_recordset
Say you need to insert a list of people with attributes into the database.
const persons = [
{
name: 'John',
tags: ['foo', 'bar']
},
{
name: 'Jane',
tags: ['baz']
}
];You may be tempted to traverse through the array and insert each record separately, e.g.
for (const person of persons) {
await pool.query(sql`
INSERT INTO person (name, tags)
VALUES (
${person.name},
${sql.array(person.tags, 'text[]')}
)
`);
}It's easier to read and grasp when working with a few records. If you're like me and troubleshoot a 2M+ insert query per day, batching inserts may be beneficial.

What prompted the search for better alternatives.
Inserting using unnest pattern might look like this:
await pool.query(sql`
INSERT INTO public.person (name, tags)
SELECT t1.name, t1.tags::text[]
FROM unnest(
${sql.array(['John', 'Jane'], 'text')},
${sql.array(['{foo,bar}', '{baz}'], 'text')}
) AS t1.(name, tags);
`);You must convert arrays into PostgreSQL array strings and provide them as text arguments, which is unsightly. Iterating the array to create slices for each column is likewise unattractive.
However, with jsonb_to_recordset, we can:
await pool.query(sql`
INSERT INTO person (name, tags)
SELECT *
FROM jsonb_to_recordset(${sql.jsonb(persons)}) AS t(name text, tags text[])
`);In contrast to the unnest approach, using jsonb_to_recordset we can easily insert complex nested data structures, and we can pass the original JSON document to the query without needing to manipulate it.
In terms of performance they are also exactly the same. As such, my current recommendation is to prefer jsonb_to_recordset whenever inserting lots of rows or nested data structures.

Dmitrii Eliuseev
1 year ago
Creating Images on Your Local PC Using Stable Diffusion AI
Deep learning-based generative art is being researched. As usual, self-learning is better. Some models, like OpenAI's DALL-E 2, require registration and can only be used online, but others can be used locally, which is usually more enjoyable for curious users. I'll demonstrate the Stable Diffusion model's operation on a standard PC.

Let’s get started.
What It Does
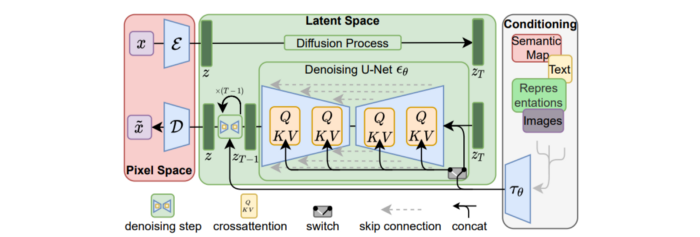
Stable Diffusion uses numerous components:
A generative model trained to produce images is called a diffusion model. The model is incrementally improving the starting data, which is only random noise. The model has an image, and while it is being trained, the reversed process is being used to add noise to the image. Being able to reverse this procedure and create images from noise is where the true magic is (more details and samples can be found in the paper).
An internal compressed representation of a latent diffusion model, which may be altered to produce the desired images, is used (more details can be found in the paper). The capacity to fine-tune the generation process is essential because producing pictures at random is not very attractive (as we can see, for instance, in Generative Adversarial Networks).
A neural network model called CLIP (Contrastive Language-Image Pre-training) is used to translate natural language prompts into vector representations. This model, which was trained on 400,000,000 image-text pairs, enables the transformation of a text prompt into a latent space for the diffusion model in the scenario of stable diffusion (more details in that paper).
This figure shows all data flow:
The weights file size for Stable Diffusion model v1 is 4 GB and v2 is 5 GB, making the model quite huge. The v1 model was trained on 256x256 and 512x512 LAION-5B pictures on a 4,000 GPU cluster using over 150.000 NVIDIA A100 GPU hours. The open-source pre-trained model is helpful for us. And we will.
Install
Before utilizing the Python sources for Stable Diffusion v1 on GitHub, we must install Miniconda (assuming Git and Python are already installed):
wget https://repo.anaconda.com/miniconda/Miniconda3-py39_4.12.0-Linux-x86_64.sh
chmod +x Miniconda3-py39_4.12.0-Linux-x86_64.sh
./Miniconda3-py39_4.12.0-Linux-x86_64.sh
conda update -n base -c defaults condaInstall the source and prepare the environment:
git clone https://github.com/CompVis/stable-diffusion
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
pip3 install transformers --upgradeDownload the pre-trained model weights next. HiggingFace has the newest checkpoint sd-v14.ckpt (a download is free but registration is required). Put the file in the project folder and have fun:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Almost. The installation is complete for happy users of current GPUs with 12 GB or more VRAM. RuntimeError: CUDA out of memory will occur otherwise. Two solutions exist.
Running the optimized version
Try optimizing first. After cloning the repository and enabling the environment (as previously), we can run the command:
python3 optimizedSD/optimized_txt2img.py --prompt "hello world" --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Stable Diffusion worked on my visual card with 8 GB RAM (alas, I did not behave well enough to get NVIDIA A100 for Christmas, so 8 GB GPU is the maximum I have;).
Running Stable Diffusion without GPU
If the GPU does not have enough RAM or is not CUDA-compatible, running the code on a CPU will be 20x slower but better than nothing. This unauthorized CPU-only branch from GitHub is easiest to obtain. We may easily edit the source code to use the latest version. It's strange that a pull request for that was made six months ago and still hasn't been approved, as the changes are simple. Readers can finish in 5 minutes:
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available at line 20 of ldm/models/diffusion/ddim.py ().
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available in line 20 of ldm/models/diffusion/plms.py ().
Replace device=cuda in lines 38, 55, 83, and 142 of ldm/modules/encoders/modules.py with device=cuda if torch.cuda.is available(), otherwise cpu.
Replace model.cuda() in scripts/txt2img.py line 28 and scripts/img2img.py line 43 with if torch.cuda.is available(): model.cuda ().
Run the script again.
Testing
Test the model. Text-to-image is the first choice. Test the command line example again:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1The slow generation takes 10 seconds on a GPU and 10 minutes on a CPU. Final image:

Hello world is dull and abstract. Try a brush-wielding hamster. Why? Because we can, and it's not as insane as Napoleon's cat. Another image:

Generating an image from a text prompt and another image is interesting. I made this picture in two minutes using the image editor (sorry, drawing wasn't my strong suit):
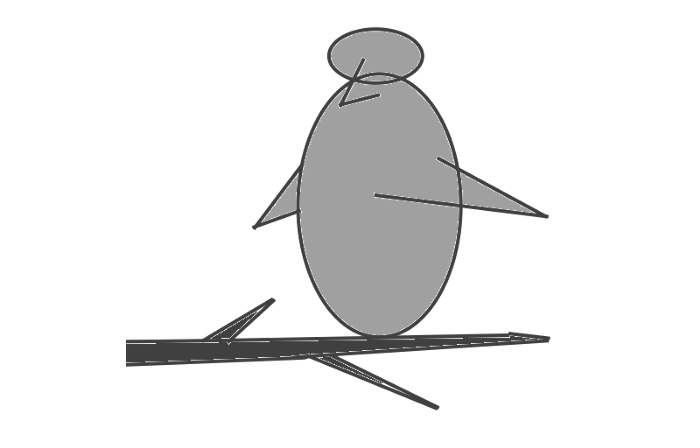
I can create an image from this drawing:
python3 scripts/img2img.py --prompt "A bird is sitting on a tree branch" --ckpt sd-v1-4.ckpt --init-img bird.png --strength 0.8It was far better than my initial drawing:

I hope readers understand and experiment.
Stable Diffusion UI
Developers love the command line, but regular users may struggle. Stable Diffusion UI projects simplify image generation and installation. Simple usage:
Unpack the ZIP after downloading it from https://github.com/cmdr2/stable-diffusion-ui/releases. Linux and Windows are compatible with Stable Diffusion UI (sorry for Mac users, but those machines are not well-suitable for heavy machine learning tasks anyway;).
Start the script.
Done. The web browser UI makes configuring various Stable Diffusion features (upscaling, filtering, etc.) easy:
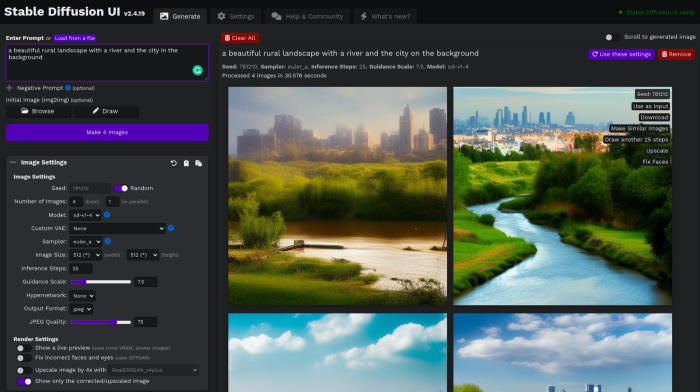
V2.1 of Stable Diffusion
I noticed the notification about releasing version 2.1 while writing this essay, and it was intriguing to test it. First, compare version 2 to version 1:
alternative text encoding. The Contrastive LanguageImage Pre-training (CLIP) deep learning model, which was trained on a significant number of text-image pairs, is used in Stable Diffusion 1. The open-source CLIP implementation used in Stable Diffusion 2 is called OpenCLIP. It is difficult to determine whether there have been any technical advancements or if legal concerns were the main focus. However, because the training datasets for the two text encoders were different, the output results from V1 and V2 will differ for the identical text prompts.
a new depth model that may be used to the output of image-to-image generation.
a revolutionary upscaling technique that can quadruple the resolution of an image.
Generally higher resolution Stable Diffusion 2 has the ability to produce both 512x512 and 768x768 pictures.
The Hugging Face website offers a free online demo of Stable Diffusion 2.1 for code testing. The process is the same as for version 1.4. Download a fresh version and activate the environment:
conda deactivate
conda env remove -n ldm # Use this if version 1 was previously installed
git clone https://github.com/Stability-AI/stablediffusion
cd stablediffusion
conda env create -f environment.yaml
conda activate ldmHugging Face offers a new weights ckpt file.
The Out of memory error prevented me from running this version on my 8 GB GPU. Version 2.1 fails on CPUs with the slow conv2d cpu not implemented for Half error (according to this GitHub issue, the CPU support for this algorithm and data type will not be added). The model can be modified from half to full precision (float16 instead of float32), however it doesn't make sense since v1 runs up to 10 minutes on the CPU and v2.1 should be much slower. The online demo results are visible. The same hamster painting with a brush prompt yielded this result:

It looks different from v1, but it functions and has a higher resolution.
The superresolution.py script can run the 4x Stable Diffusion upscaler locally (the x4-upscaler-ema.ckpt weights file should be in the same folder):
python3 scripts/gradio/superresolution.py configs/stable-diffusion/x4-upscaling.yaml x4-upscaler-ema.ckptThis code allows the web browser UI to select the image to upscale:
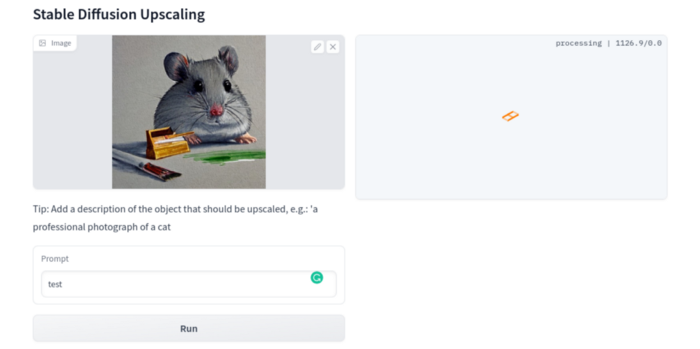
The copy-paste strategy may explain why the upscaler needs a text prompt (and the Hugging Face code snippet does not have any text input as well). I got a GPU out of memory error again, although CUDA can be disabled like v1. However, processing an image for more than two hours is unlikely:
Stable Diffusion Limitations
When we use the model, it's fun to see what it can and can't do. Generative models produce abstract visuals but not photorealistic ones. This fundamentally limits The generative neural network was trained on text and image pairs, but humans have a lot of background knowledge about the world. The neural network model knows nothing. If someone asks me to draw a Chinese text, I can draw something that looks like Chinese but is actually gibberish because I never learnt it. Generative AI does too! Humans can learn new languages, but the Stable Diffusion AI model includes only language and image decoder brain components. For instance, the Stable Diffusion model will pull NO WAR banner-bearers like this:
V1:

V2.1:

The shot shows text, although the model never learned to read or write. The model's string tokenizer automatically converts letters to lowercase before generating the image, so typing NO WAR banner or no war banner is the same.
I can also ask the model to draw a gorgeous woman:
V1:

V2.1:

The first image is gorgeous but physically incorrect. A second one is better, although it has an Uncanny valley feel. BTW, v2 has a lifehack to add a negative prompt and define what we don't want on the image. Readers might try adding horrible anatomy to the gorgeous woman request.
If we ask for a cartoon attractive woman, the results are nice, but accuracy doesn't matter:
V1:

V2.1:

Another example: I ordered a model to sketch a mouse, which looks beautiful but has too many legs, ears, and fingers:
V1:

V2.1: improved but not perfect.

V1 produces a fun cartoon flying mouse if I want something more abstract:

I tried multiple times with V2.1 but only received this:

The image is OK, but the first version is closer to the request.
Stable Diffusion struggles to draw letters, fingers, etc. However, abstract images yield interesting outcomes. A rural landscape with a modern metropolis in the background turned out well:
V1:

V2.1:

Generative models help make paintings too (at least, abstract ones). I searched Google Image Search for modern art painting to see works by real artists, and this was the first image:

I typed "abstract oil painting of people dancing" and got this:
V1:

V2.1:

It's a different style, but I don't think the AI-generated graphics are worse than the human-drawn ones.
The AI model cannot think like humans. It thinks nothing. A stable diffusion model is a billion-parameter matrix trained on millions of text-image pairs. I input "robot is creating a picture with a pen" to create an image for this post. Humans understand requests immediately. I tried Stable Diffusion multiple times and got this:

This great artwork has a pen, robot, and sketch, however it was not asked. Maybe it was because the tokenizer deleted is and a words from a statement, but I tried other requests such robot painting picture with pen without success. It's harder to prompt a model than a person.
I hope Stable Diffusion's general effects are evident. Despite its limitations, it can produce beautiful photographs in some settings. Readers who want to use Stable Diffusion results should be warned. Source code examination demonstrates that Stable Diffusion images feature a concealed watermark (text StableDiffusionV1 and SDV2) encoded using the invisible-watermark Python package. It's not a secret, because the official Stable Diffusion repository's test watermark.py file contains a decoding snippet. The put watermark line in the txt2img.py source code can be removed if desired. I didn't discover this watermark on photographs made by the online Hugging Face demo. Maybe I did something incorrectly (but maybe they are just not using the txt2img script on their backend at all).
Conclusion
The Stable Diffusion model was fascinating. As I mentioned before, trying something yourself is always better than taking someone else's word, so I encourage readers to do the same (including this article as well;).
Is Generative AI a game-changer? My humble experience tells me:
I think that place has a lot of potential. For designers and artists, generative AI can be a truly useful and innovative tool. Unfortunately, it can also pose a threat to some of them since if users can enter a text field to obtain a picture or a website logo in a matter of clicks, why would they pay more to a different party? Is it possible right now? unquestionably not yet. Images still have a very poor quality and are erroneous in minute details. And after viewing the image of the stunning woman above, models and fashion photographers may also unwind because it is highly unlikely that AI will replace them in the upcoming years.
Today, generative AI is still in its infancy. Even 768x768 images are considered to be of a high resolution when using neural networks, which are computationally highly expensive. There isn't an AI model that can generate high-resolution photographs natively without upscaling or other methods, at least not as of the time this article was written, but it will happen eventually.
It is still a challenge to accurately represent knowledge in neural networks (information like how many legs a cat has or the year Napoleon was born). Consequently, AI models struggle to create photorealistic photos, at least where little details are important (on the other side, when I searched Google for modern art paintings, the results are often even worse;).
When compared to the carefully chosen images from official web pages or YouTube reviews, the average output quality of a Stable Diffusion generation process is actually less attractive because to its high degree of randomness. When using the same technique on their own, consumers will theoretically only view those images as 1% of the results.
Anyway, it's exciting to witness this area's advancement, especially because the project is open source. Google's Imagen and DALL-E 2 can also produce remarkable findings. It will be interesting to see how they progress.

Clive Thompson
1 year ago
Small Pieces of Code That Revolutionized the World
Few sentences can have global significance.

Ethan Zuckerman invented the pop-up commercial in 1997.
He was working for Tripod.com, an online service that let people make little web pages for free. Tripod offered advertising to make money. Advertisers didn't enjoy seeing their advertising next to filthy content, like a user's anal sex website.
Zuckerman's boss wanted a solution. Wasn't there a way to move the ads away from user-generated content?
When you visited a Tripod page, a pop-up ad page appeared. So, the ad isn't officially tied to any user page. It'd float onscreen.
Here’s the thing, though: Zuckerman’s bit of Javascript, that created the popup ad? It was incredibly short — a single line of code:
window.open('http://tripod.com/navbar.html'
"width=200, height=400, toolbar=no, scrollbars=no, resizable=no, target=_top");Javascript tells the browser to open a 200-by-400-pixel window on top of any other open web pages, without a scrollbar or toolbar.
Simple yet harmful! Soon, commercial websites mimicked Zuckerman's concept, infesting the Internet with pop-up advertising. In the early 2000s, a coder for a download site told me that most of their revenue came from porn pop-up ads.
Pop-up advertising are everywhere. You despise them. Hopefully, your browser blocks them.
Zuckerman wrote a single line of code that made the world worse.

I read Zuckerman's story in How 26 Lines of Code Changed the World. Torie Bosch compiled a humorous anthology of short writings about code that tipped the world.
Most of these samples are quite short. Pop-cultural preconceptions about coding say that important code is vast and expansive. Hollywood depicts programmers as blurs spouting out Niagaras of code. Google's success was formerly attributed to its 2 billion lines of code.
It's usually not true. Google's original breakthrough, the piece of code that propelled Google above its search-engine counterparts, was its PageRank algorithm, which determined a web page's value based on how many other pages connected to it and the quality of those connecting pages. People have written their own Python versions; it's only a few dozen lines.
Google's operations, like any large tech company's, comprise thousands of procedures. So their code base grows. The most impactful code can be brief.
The examples are fascinating and wide-ranging, so read the whole book (or give it to nerds as a present). Charlton McIlwain wrote a chapter on the police beat algorithm developed in the late 1960s to anticipate crime hotspots so law enforcement could dispatch more officers there. It created a racial feedback loop. Since poor Black neighborhoods were already overpoliced compared to white ones, the algorithm directed more policing there, resulting in more arrests, which convinced it to send more police; rinse and repeat.
Kelly Chudler's You Are Not Expected To Understand This depicts the police-beat algorithm.

Even shorter code changed the world: the tracking pixel.
Lily Hay Newman's chapter on monitoring pixels says you probably interact with this code every day. It's a snippet of HTML that embeds a single tiny pixel in an email. Getting an email with a tracking code spies on me. As follows: My browser requests the single-pixel image as soon as I open the mail. My email sender checks to see if Clives browser has requested that pixel. My email sender can tell when I open it.
Adding a tracking pixel to an email is easy:
<img src="URL LINKING TO THE PIXEL ONLINE" width="0" height="0">An older example: Ellen R. Stofan and Nick Partridge wrote a chapter on Apollo 11's lunar module bailout code. This bailout code operated on the lunar module's tiny on-board computer and was designed to prioritize: If the computer grew overloaded, it would discard all but the most vital work.
When the lunar module approached the moon, the computer became overloaded. The bailout code shut down anything non-essential to landing the module. It shut down certain lunar module display systems, scaring the astronauts. Module landed safely.
22-line code
POODOO INHINT
CA Q
TS ALMCADR
TC BANKCALL
CADR VAC5STOR # STORE ERASABLES FOR DEBUGGING PURPOSES.
INDEX ALMCADR
CAF 0
ABORT2 TC BORTENT
OCT77770 OCT 77770 # DONT MOVE
CA V37FLBIT # IS AVERAGE G ON
MASK FLAGWRD7
CCS A
TC WHIMPER -1 # YES. DONT DO POODOO. DO BAILOUT.
TC DOWNFLAG
ADRES STATEFLG
TC DOWNFLAG
ADRES REINTFLG
TC DOWNFLAG
ADRES NODOFLAG
TC BANKCALL
CADR MR.KLEAN
TC WHIMPERThis fun book is worth reading.
I'm a contributor to the New York Times Magazine, Wired, and Mother Jones. I've also written Coders: The Making of a New Tribe and the Remaking of the World and Smarter Than You Think: How Technology is Changing Our Minds. Twitter and Instagram: @pomeranian99; Mastodon: @clive@saturation.social.
You might also like

Matthew Cluff
1 year ago
GTO Poker 101
"GTO" (Game Theory Optimal) has been used a lot in poker recently. To clarify its meaning and application, the aim of this article is to define what it is, when to use it when playing, what strategies to apply for how to play GTO poker, for beginner and more advanced players!
Poker GTO
In poker, you can choose between two main winning strategies:
Exploitative play maximizes expected value (EV) by countering opponents' sub-optimal plays and weaker tendencies. Yes, playing this way opens you up to being exploited, but the weaker opponents you're targeting won't change their game to counteract this, allowing you to reap maximum profits over the long run.
GTO (Game-Theory Optimal): You try to play perfect poker, which forces your opponents to make mistakes (which is where almost all of your profit will be derived from). It mixes bluffs or semi-bluffs with value bets, clarifies bet sizes, and more.
GTO vs. Exploitative: Which is Better in Poker?
Before diving into GTO poker strategy, it's important to know which of these two play styles is more profitable for beginners and advanced players. The simple answer is probably both, but usually more exploitable.
Most players don't play GTO poker and can be exploited in their gameplay and strategy, allowing for more profits to be made using an exploitative approach. In fact, it’s only in some of the largest games at the highest stakes that GTO concepts are fully utilized and seen in practice, and even then, exploitative plays are still sometimes used.
Knowing, understanding, and applying GTO poker basics will create a solid foundation for your poker game. It's also important to understand GTO so you can deviate from it to maximize profits.
GTO Poker Strategy
According to Ed Miller's book "Poker's 1%," the most fundamental concept that only elite poker players understand is frequency, which could be in relation to cbets, bluffs, folds, calls, raises, etc.
GTO poker solvers (downloadable online software) give solutions for how to play optimally in any given spot and often recommend using mixed strategies based on select frequencies.
In a river situation, a solver may tell you to call 70% of the time and fold 30%. It may also suggest calling 50% of the time, folding 35% of the time, and raising 15% of the time (with a certain range of hands).
Frequencies are a fundamental and often unrecognized part of poker, but they run through these 5 GTO concepts.
1. Preflop ranges
To compensate for positional disadvantage, out-of-position players must open tighter hand ranges.
Premium starting hands aren't enough, though. Considering GTO poker ranges and principles, you want a good, balanced starting hand range from each position with at least some hands that can make a strong poker hand regardless of the flop texture (low, mid, high, disconnected, etc).
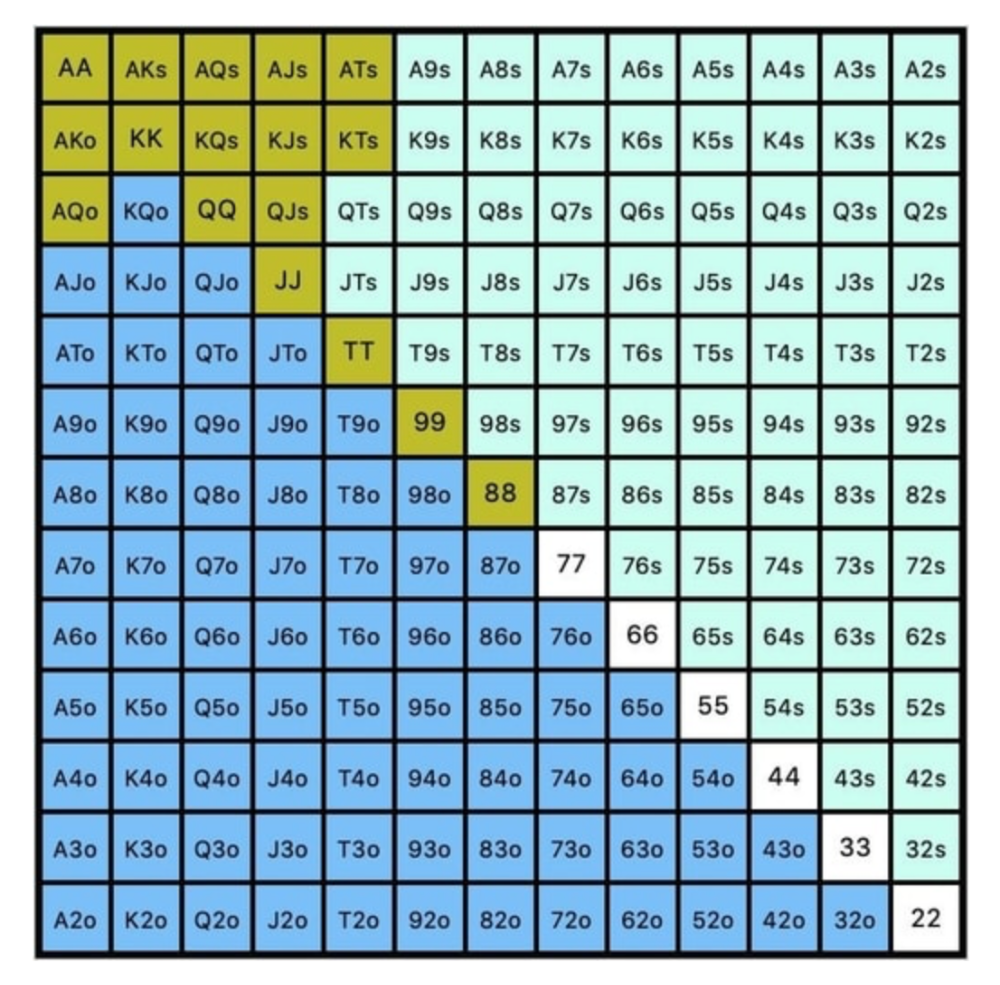
Below is a GTO preflop beginner poker chart for online 6-max play, showing which hand ranges one should open-raise with. Table positions are color-coded (see key below).
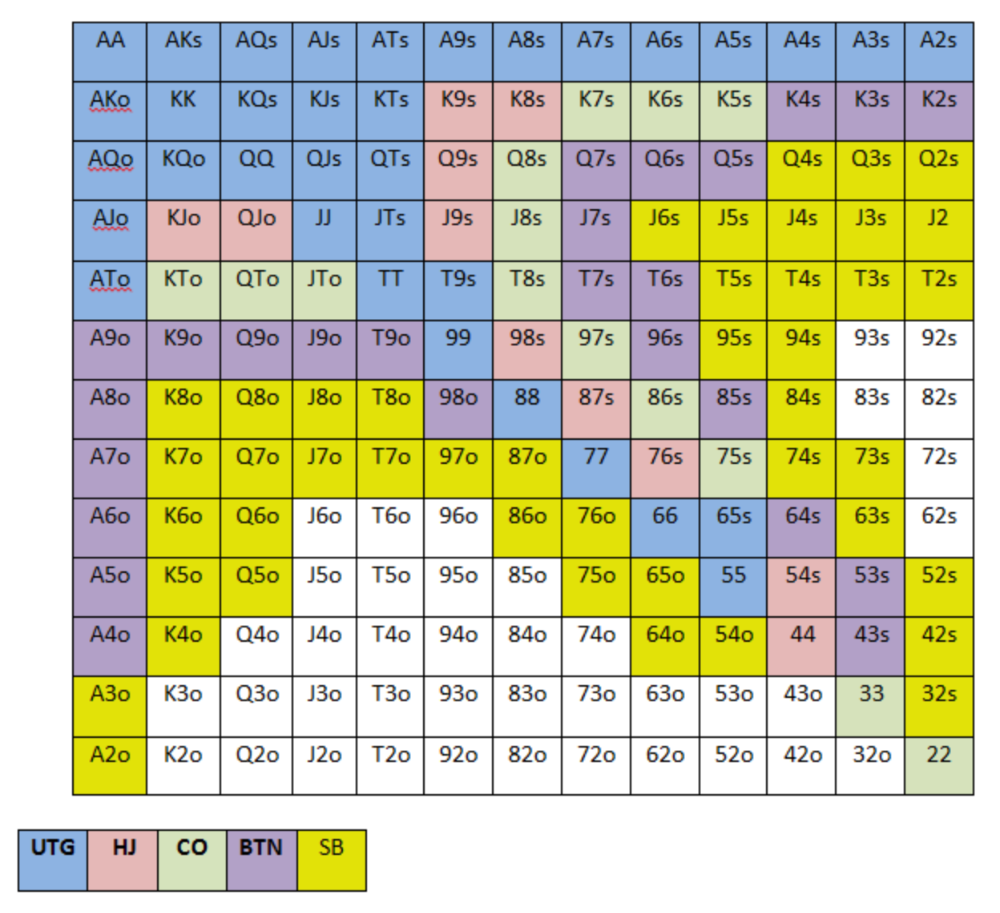
NOTE: For GTO play, it's advisable to use a mixed strategy for opening in the small blind, combining open-limps and open-raises for various hands. This cannot be illustrated with the color system used for the chart.
Choosing which hands to play is often a math problem, as discussed below.
Other preflop GTO poker charts include which hands to play after a raise, which to 3bet, etc. Solvers can help you decide which preflop hands to play (call, raise, re-raise, etc.).
2. Pot Odds
Always make +EV decisions that profit you as a poker player. Understanding pot odds (and equity) can help.
Postflop Pot Odds
Let’s say that we have JhTh on a board of 9h8h2s4c (open-ended straight-flush draw). We have $40 left and $50 in the pot. He has you covered and goes all-in. As calling or folding are our only options, playing GTO involves calculating whether a call is +EV or –EV. (The hand was empty.)
Any remaining heart, Queen, or 7 wins the hand. This means we can improve 15 of 46 unknown cards, or 32.6% of the time.
What if our opponent has a set? The 4h or 2h could give us a flush, but it could also give the villain a boat. If we reduce outs from 15 to 14.5, our equity would be 31.5%.
We must now calculate pot odds.
(bet/(our bet+pot)) = pot odds
= $50 / ($40 + $90)
= $40 / $130
= 30.7%
To make a profitable call, we need at least 30.7% equity. This is a profitable call as we have 31.5% equity (even if villain has a set). Yes, we will lose most of the time, but we will make a small profit in the long run, making a call correct.
Pot odds aren't just for draws, either. If an opponent bets 50% pot, you get 3 to 1 odds on a call, so you must win 25% of the time to be profitable. If your current hand has more than 25% equity against your opponent's perceived range, call.
Preflop Pot Odds
Preflop, you raise to 3bb and the button 3bets to 9bb. You must decide how to act. In situations like these, we can actually use pot odds to assist our decision-making.
This pot is:
(our open+3bet size+small blind+big blind)
(3bb+9bb+0.5bb+1bb)
= 13.5
This means we must call 6bb to win a pot of 13.5bb, which requires 30.7% equity against the 3bettor's range.
Three additional factors must be considered:
Being out of position on our opponent makes it harder to realize our hand's equity, as he can use his position to put us in tough spots. To profitably continue against villain's hand range, we should add 7% to our equity.
Implied Odds / Reverse Implied Odds: The ability to win or lose significantly more post-flop (than pre-flop) based on our remaining stack.
While statistics on 3bet stats can be gained with a large enough sample size (i.e. 8% 3bet stat from button), the numbers don't tell us which 8% of hands villain could be 3betting with. Both polarized and depolarized charts below show 8% of possible hands.
7.4% of hands are depolarized.
Polarized Hand range (7.54%):
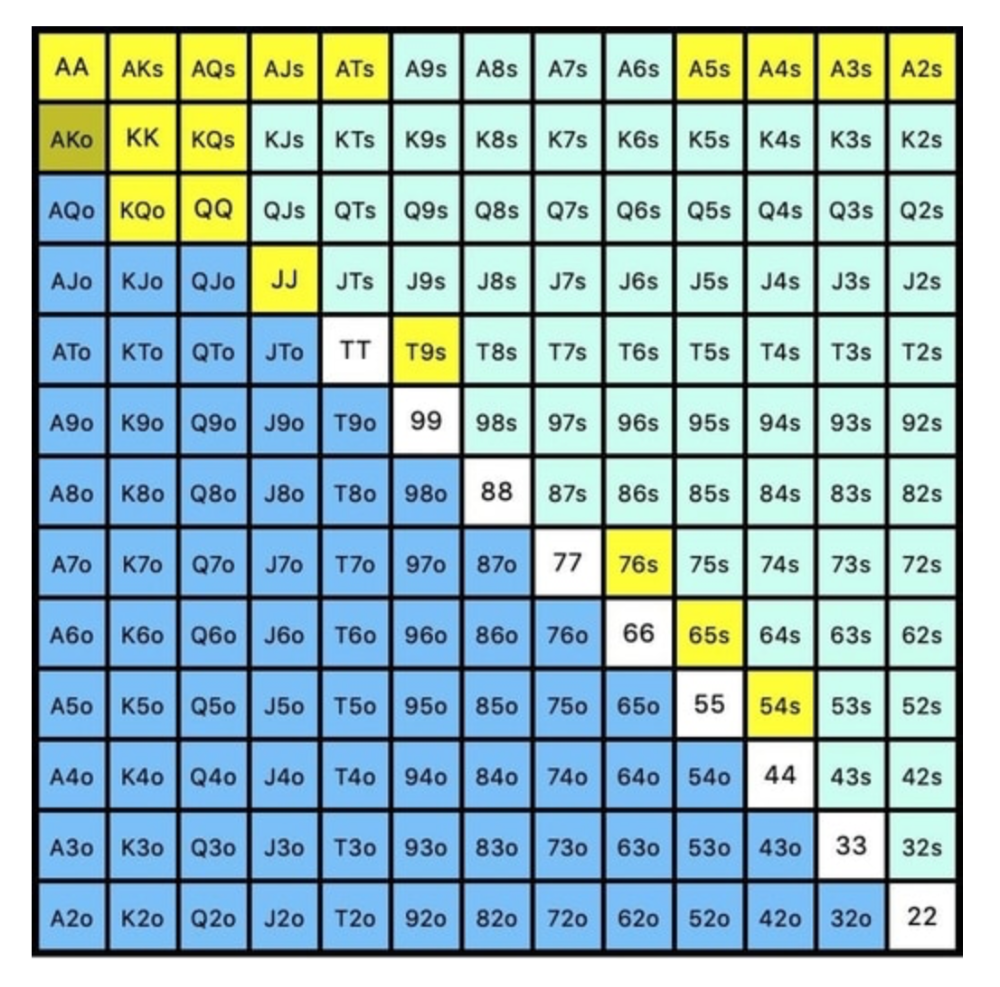
Each hand range has different contents. We don't know if he 3bets some hands and calls or folds others.
Using an exploitable strategy can help you play a hand range correctly. The next GTO concept will make things easier.
3. Minimum Defense Frequency:
This concept refers to the % of our range we must continue with (by calling or raising) to avoid being exploited by our opponents. This concept is most often used off-table and is difficult to apply in-game.
These beginner GTO concepts will help your decision-making during a hand, especially against aggressive opponents.
MDF formula:
MDF = POT SIZE/(POT SIZE+BET SIZE)
Here's a poker GTO chart of common bet sizes and minimum defense frequency.
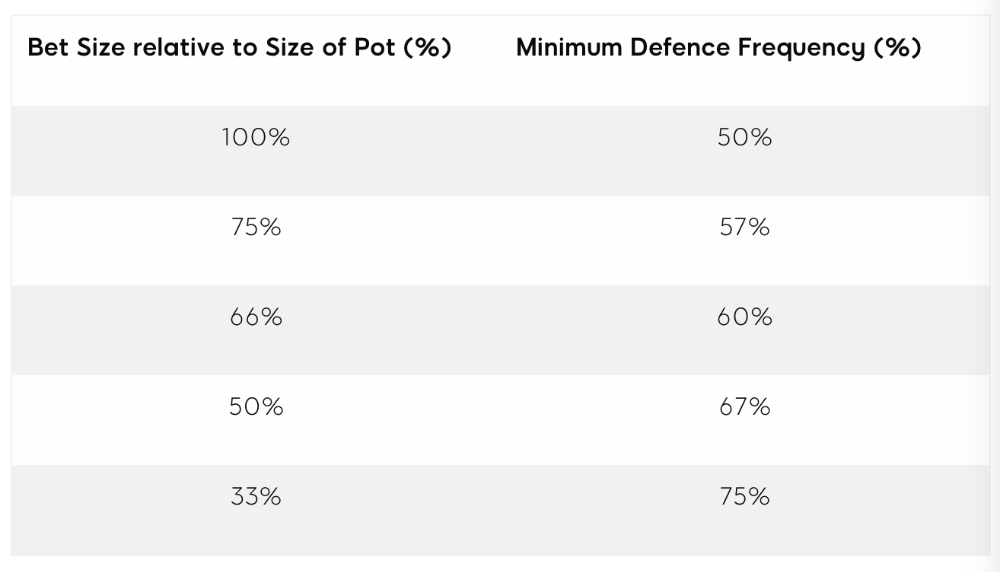
Take the number of hand combos in your starting hand range and use the MDF to determine which hands to continue with. Choose hands with the most playability and equity against your opponent's betting range.
Say you open-raise HJ and BB calls. Qh9h6c flop. Your opponent leads you for a half-pot bet. MDF suggests keeping 67% of our range.
Using the above starting hand chart, we can determine that the HJ opens 254 combos:
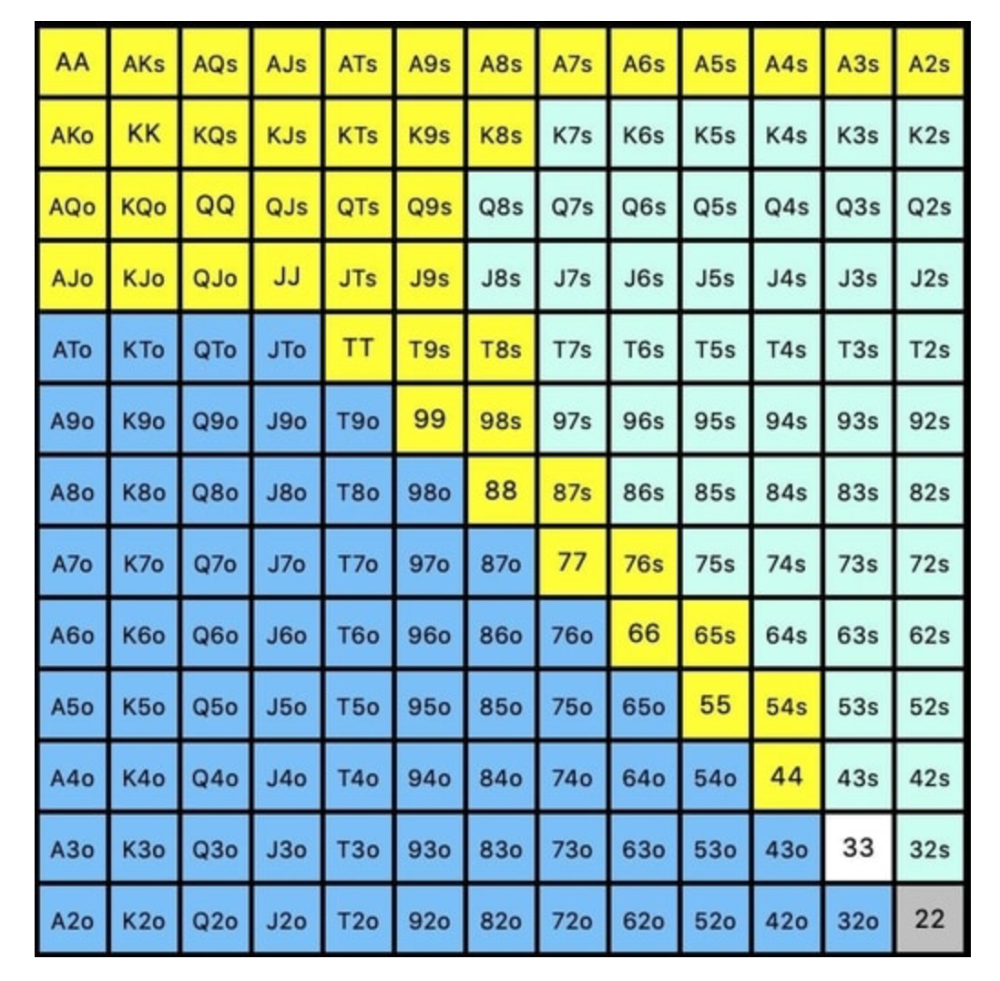
We must defend 67% of these hands, or 170 combos, according to MDF. Hands we should keep include:
Flush draws
Open-Ended Straight Draws
Gut-Shot Straight Draws
Overcards
Any Pair or better
So, our flop continuing range could be:
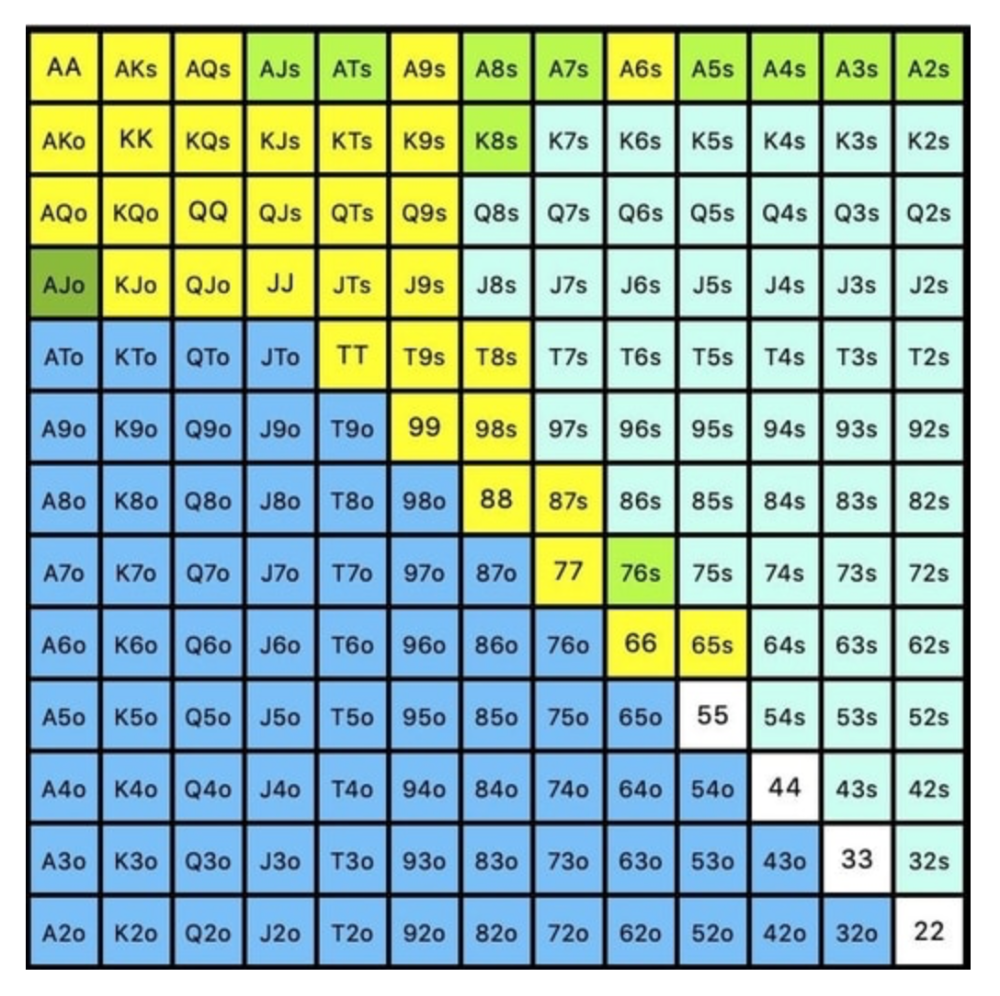
Some highlights:
Fours and fives have little chance of improving on the turn or river.
We only continue with AX hearts (with a flush draw) without a pair or better.
We'll also include 4 AJo combos, all of which have the Ace of hearts, and AcJh, which can block a backdoor nut flush combo.
Let's assume all these hands are called and the turn is blank (2 of spades). Opponent bets full-pot. MDF says we must defend 50% of our flop continuing range, or 85 of 170 combos, to be unexploitable. This strategy includes our best flush draws, straight draws, and made hands.
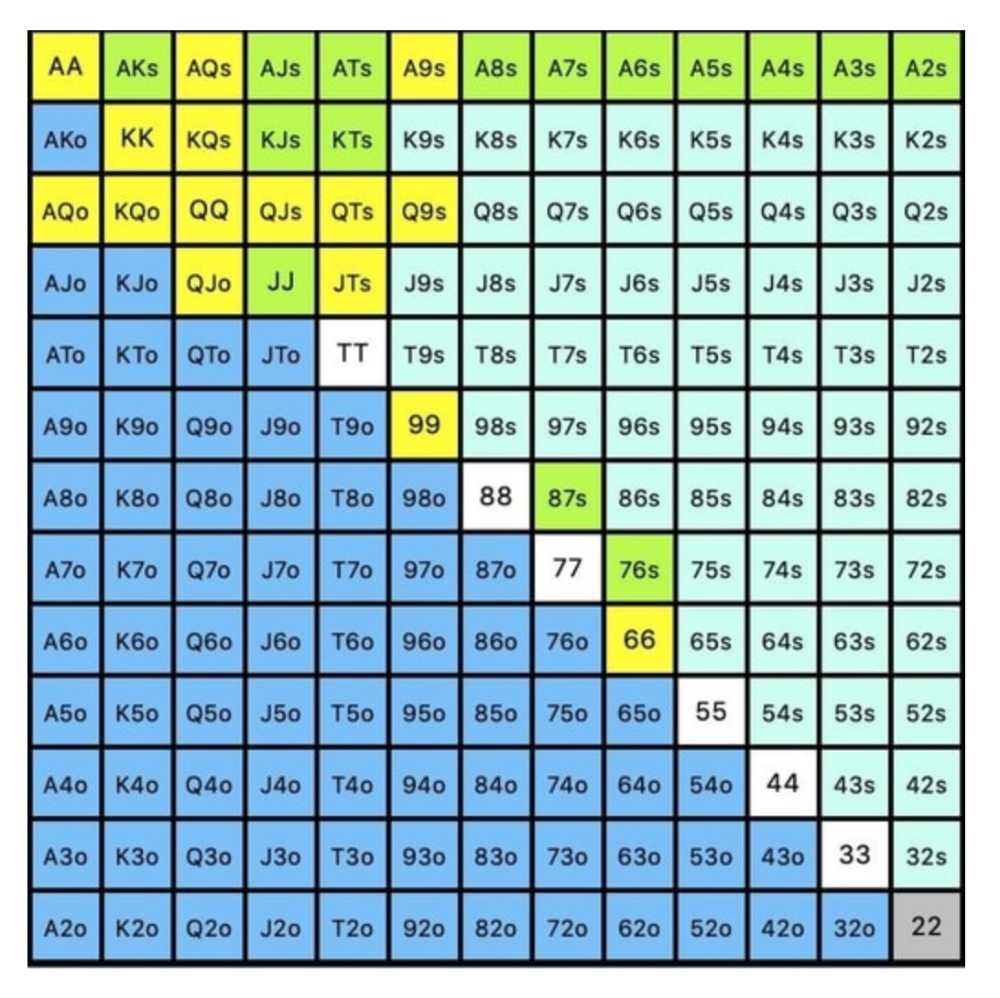
Here, we keep combining:
Nut flush draws
Pair + flush draws
GS + flush draws
Second Pair, Top Kicker+
One combo of JJ that doesn’t block the flush draw or backdoor flush draw.
On the river, we can fold our missed draws and keep our best made hands. When calling with weaker hands, consider blocker effects and card removal to avoid overcalling and decide which combos to continue.
4. Poker GTO Bet Sizing
To avoid being exploited, balance your bluffs and value bets. Your betting range depends on how much you bet (in relation to the pot). This concept only applies on the river, as draws (bluffs) on the flop and turn still have equity (and are therefore total bluffs).
On the flop, you want a 2:1 bluff-to-value-bet ratio. On the flop, there won't be as many made hands as on the river, and your bluffs will usually contain equity. The turn should have a "bluffing" ratio of 1:1. Use the chart below to determine GTO river bluff frequencies (relative to your bet size):
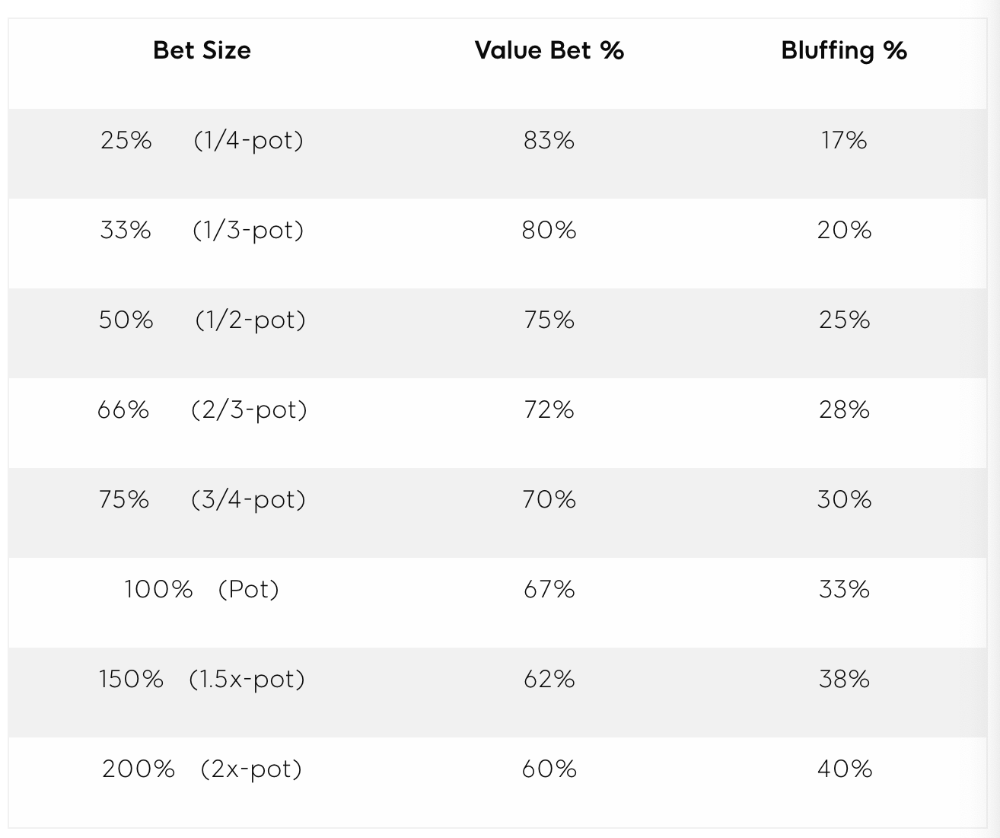
This chart relates to your opponent's pot odds. If you bet 50% pot, your opponent gets 3:1 odds and must win 25% of the time to call. Poker GTO theory suggests including 25% bluff combinations in your betting range so you're indifferent to your opponent calling or folding.
Best river bluffs don't block hands you want your opponent to have (or not have). For example, betting with missed Ace-high flush draws is often a mistake because you block a missed flush draw you want your opponent to have when bluffing on the river (meaning that it would subsequently be less likely he would have it, if you held two of the flush draw cards). Ace-high usually has some river showdown value.
If you had a 3-flush on the river and wanted to raise, you could bluff raise with AX combos holding the bluff suit Ace. Blocking the nut flush prevents your opponent from using that combo.
5. Bet Sizes and Frequency
GTO beginner strategies aren't just bluffs and value bets. They show how often and how much to bet in certain spots. Top players have benefited greatly from poker solvers, which we'll discuss next.
GTO Poker Software
In recent years, various poker GTO solvers have been released to help beginner, intermediate, and advanced players play balanced/GTO poker in various situations.
PokerSnowie and PioSolver are popular GTO and poker study programs.
While you can't compute players' hand ranges and what hands to bet or check with in real time, studying GTO play strategies with these programs will pay off. It will improve your poker thinking and understanding.
Solvers can help you balance ranges, choose optimal bet sizes, and master cbet frequencies.
GTO Poker Tournament
Late-stage tournaments have shorter stacks than cash games. In order to follow GTO poker guidelines, Nash charts have been created, tweaked, and used for many years (and also when to call, depending on what number of big blinds you have when you find yourself shortstacked).
The charts are for heads-up push/fold. In a multi-player game, the "pusher" chart can only be used if play is folded to you in the small blind. The "caller" chart can only be used if you're in the big blind and assumes a small blind "pusher" (with a much wider range than if a player in another position was open-shoving).
Divide the pusher chart's numbers by 2 to see which hand to use from the Button. Divide the original chart numbers by 4 to find the CO's pushing range. Some of the figures will be impossible to calculate accurately for the CO or positions to the right of the blinds because the chart's highest figure is "20+" big blinds, which is also used for a wide range of hands in the push chart.
Both of the GTO charts below are ideal for heads-up play, but exploitable HU shortstack strategies can lead to more +EV decisions against certain opponents. Following the charts will make your play GTO and unexploitable.
Poker pro Max Silver created the GTO push/fold software SnapShove. (It's accessible online at www.snapshove.com or as iOS or Android apps.)
Players can access GTO shove range examples in the full version. (You can customize the number of big blinds you have, your position, the size of the ante, and many other options.)
In Conclusion
Due to the constantly changing poker landscape, players are always improving their skills. Exploitable strategies often yield higher profit margins than GTO-based approaches, but knowing GTO beginner and advanced concepts can give you an edge for a few reasons.
It creates a solid gameplay base.
Having a baseline makes it easier to exploit certain villains.
You can avoid leveling wars with your opponents by making sound poker decisions based on GTO strategy.
It doesn't require assuming opponents' play styles.
Not results-oriented.
This is just the beginning of GTO and poker theory. Consider investing in the GTO poker solver software listed above to improve your game.

Jared Heyman
1 year ago
The survival and demise of Y Combinator startups
I've written a lot about Y Combinator's success, but as any startup founder or investor knows, many startups fail.
Rebel Fund invests in the top 5-10% of new Y Combinator startups each year, so we focus on identifying and supporting the most promising technology startups in our ecosystem. Given the power law dynamic and asymmetric risk/return profile of venture capital, we worry more about our successes than our failures. Since the latter still counts, this essay will focus on the proportion of YC startups that fail.
Since YC's launch in 2005, the figure below shows the percentage of active, inactive, and public/acquired YC startups by batch.
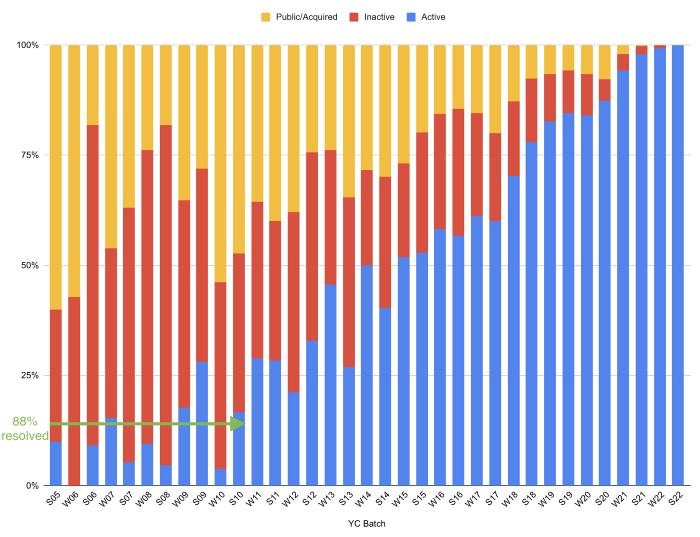
As more startups finish, the blue bars (active) decrease significantly. By 12 years, 88% of startups have closed or exited. Only 7% of startups reach resolution each year.
YC startups by status after 12 years:
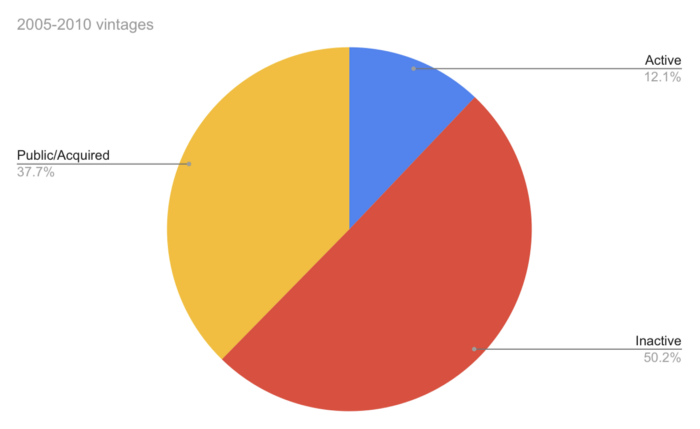
Half the startups have failed, over one-third have exited, and the rest are still operating.
In venture investing, it's said that failed investments show up before successful ones. This is true for YC startups, but only in their early years.
Below, we only present resolved companies from the first chart. Some companies fail soon after establishment, but after a few years, the inactive vs. public/acquired ratio stabilizes around 55:45. After a few years, a YC firm is roughly as likely to quit as fail, which is better than I imagined.
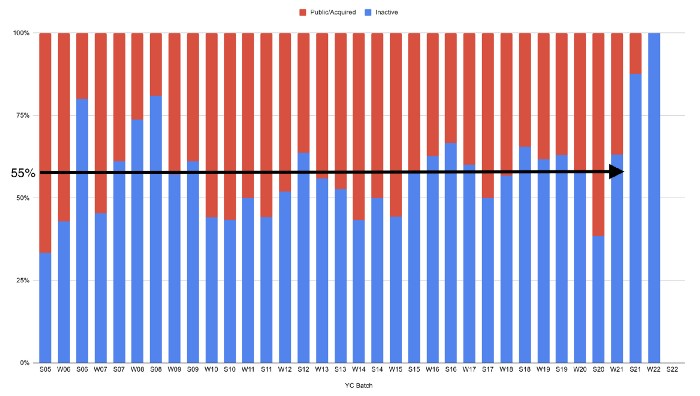
I prepared this post because Rebel investors regularly question me about YC startup failure rates and how long it takes for them to exit or shut down.
Early-stage venture investors can overlook it because 100x investments matter more than 0x investments.
YC founders can ignore it because it shouldn't matter if many of their peers succeed or fail ;)

Crypto Zen Monk
1 year ago
How to DYOR in the world of cryptocurrency
RESEARCH
We must create separate ideas and handle our own risks to be better investors. DYOR is crucial.
The only thing unsustainable is your cluelessness.
DYOR: Why
On social media, there is a lot of false information and divergent viewpoints. All of these facts might be accurate, but they might not be appropriate for your portfolio and investment preferences.
You become a more knowledgeable investor thanks to DYOR.
DYOR improves your portfolio's risk management.
My DYOR resources are below.

Messari: Major Blockchains' Activities
New York-based Messari provides cryptocurrency open data libraries.
Major blockchains offer 24-hour on-chain volume. https://messari.io/screener/most-active-chains-DB01F96B
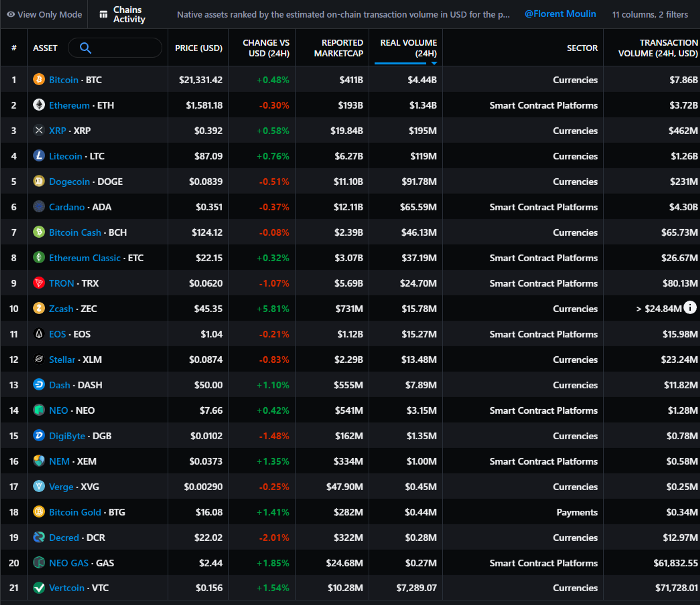
What to do
Invest in stable cryptocurrencies. Sort Messari by Real Volume (24H) or Reported Market Cap.
Coingecko: Research on Ecosystems
Top 10 Ecosystems by Coingecko are good.
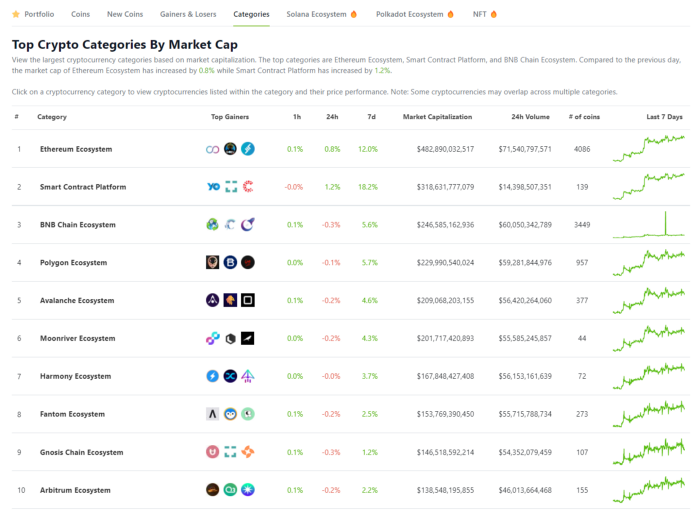
What to do
Invest in quality.
Leading ten Ecosystems by Market Cap
There are a lot of coins in the ecosystem (second last column of above chart)
CoinGecko's Market Cap Crypto Categories Market capitalization-based cryptocurrency categories. Ethereum Ecosystem www.coingecko.com
Fear & Greed Index for Bitcoin (FGI)
The Bitcoin market sentiment index ranges from 0 (extreme dread) to 100. (extreme greed).
How to Apply
See market sentiment:
Extreme fright = opportunity to buy
Extreme greed creates sales opportunity (market due for correction).
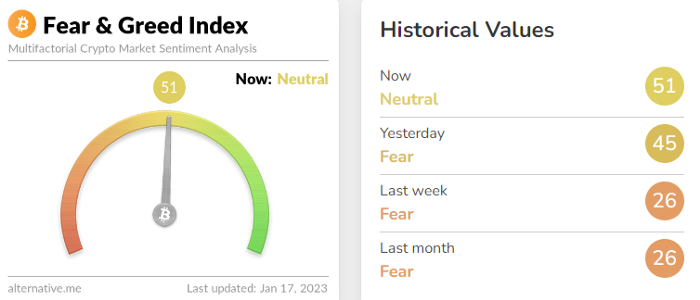
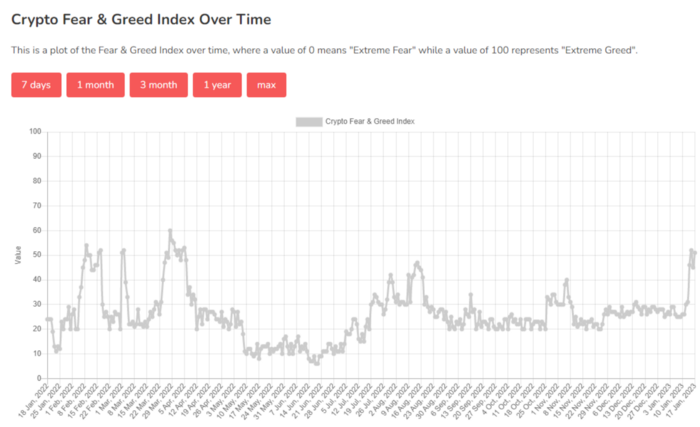
Glassnode
Glassnode gives facts, information, and confidence to make better Bitcoin, Ethereum, and cryptocurrency investments and trades.
Explore free and paid metrics.
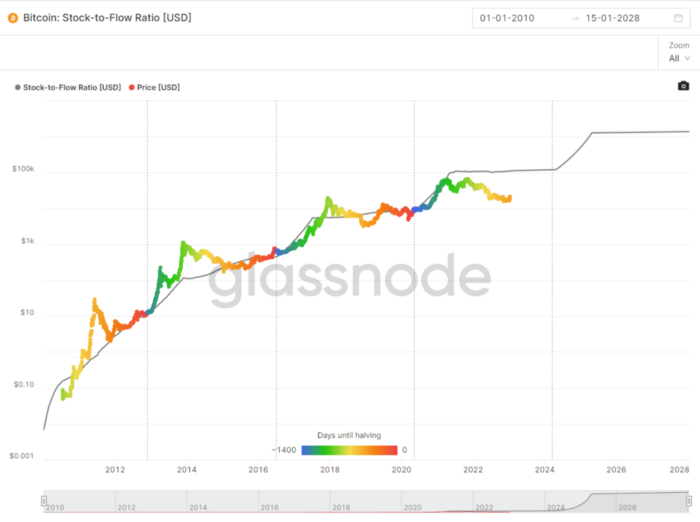
Stock to Flow Ratio: Application
The popular Stock to Flow Ratio concept believes scarcity drives value. Stock to flow is the ratio of circulating Bitcoin supply to fresh production (i.e. newly mined bitcoins). The S/F Ratio has historically predicted Bitcoin prices. PlanB invented this metric.
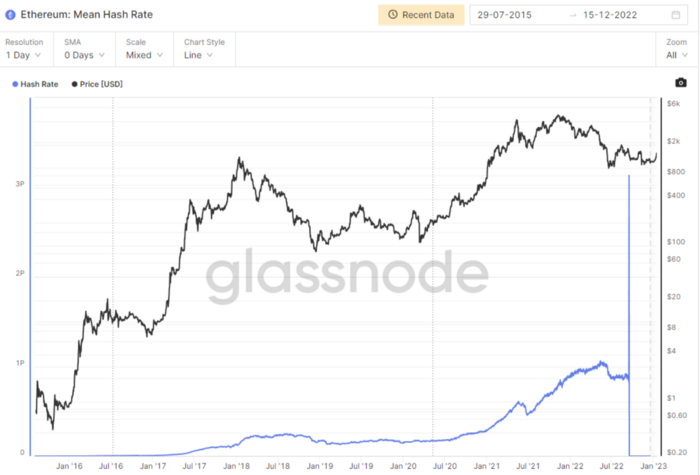
Utilization: Ethereum Hash Rate
Ethereum miners produce an estimated number of hashes per second.
ycharts: Hash rate of the Bitcoin network
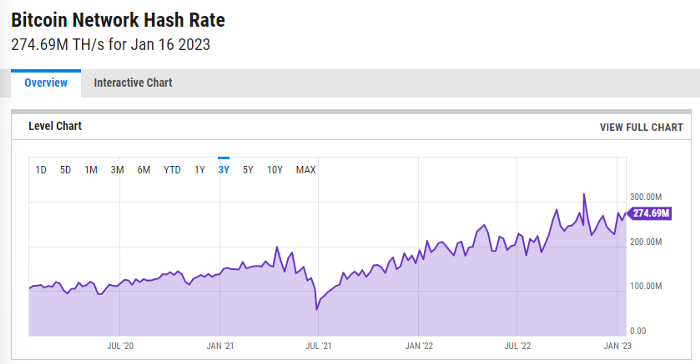
TradingView
TradingView is your go-to tool for investment analysis, watch lists, technical analysis, and recommendations from other traders/investors.
Research for a cryptocurrency project
Two key questions every successful project must ask: Q1: What is this project trying to solve? Is it a big problem or minor? Q2: How does this project make money?
Each cryptocurrency:
Check out the white paper.
check out the project's internet presence on github, twitter, and medium.
the transparency of it
Verify the team structure and founders. Verify their LinkedIn profile, academic history, and other qualifications. Search for their names with scam.
Where to purchase and use cryptocurrencies Is it traded on trustworthy exchanges?
From CoinGecko and CoinMarketCap, we may learn about market cap, circulations, and other important data.
The project must solve a problem. Solving a problem is the goal of the founders.
Avoid projects that resemble multi-level marketing or ponzi schemes.
Your use of social media
Use social media carefully or ignore it: Twitter, TradingView, and YouTube
Someone said this before and there are some truth to it. Social media bullish => short.
Your Behavior
Investigate. Spend time. You decide. Worth it!
Only you have the best interest in your financial future.